Team: Sampath Chanda (schanda) and Harish Dixit (hdixit)
Final Project Report
Overview
We have accelerated the frame processing of video feed from Facebook 3D-360 camera system to produce a fully stitched image for stereo vision. Our acceleration techniques utilized CPU Multithreading and GPU acceleration to exploit pixel level parallelism for stitching frames together to produce a complete 360 degree vision. We got a speedup of around 3.3x for optical flow phase and 86.5x for Sharpening phase of the algorithm at an SSIM (Structural Similarity) to the original image at 93% (on average) .

Please refer to Checkpoint link below to refer to Checkpoint Updates:
Proposal
Checkpoint
Motivation and Background
Virtual reality has the power of changing the way that we see and interact with the world. The very concept of being able to perceive a different environment other than the one we are actually in, opens up a huge space of possibilities for innovative applications and technologies. One key method of generating a VR environment is using a 360 degree camera to record, process and buffer a 360 degree video. But rendering a high quality video would require processing single camera frames to produce a stitched larger frame and this process is highly compute intensive. Facebook Surround360 camera rig is a 3D-360 camera system that captures frames from 17 cameras at 30-60 fps to cover the overall 360 degree vision. Just to render a properly stitched image from one time instance (17 frames), current multithreaded implementation of Facebook code takes around 66 seconds on AWS (8 core Intel Xeon E5-2670, 15GB RAM). This converts into a whopping 1980 minutes to render a 1 minute video at 30 fps. Such a high compute time could discourage a wider adaptability of this technology. With a goal of alleviating such dramatic compute latencies, we targeted to accelerate the frame processing of a 360 degree video.Challenges
We identify few challenges in our overall implementation of the project. For a start, we are competing with a well-written Multi-threaded program from Facebook Engineers. Both of the project members are newbies to the field of Computer Vision and we were constantly trying to learn and understand the algorithm, and reason out what can be parallelised and what cannot be. We also observed that the since the codebase from Facebook was huge (>20000 Lines of Code), and had no support or handles in any of the scripts for GPU integration, we had to build the entire GPU environment for the Facebook code from scratch. Right from the integration to CMake Build to the linking order of different interfaces to the CUDA framework, we had to work through all the issues. To give an idea of how complex the Facebook build flow is, if you currently take the git repo for the code and attempt to build it, the build would fail. We had to track 3 different version histories and note the dependencies and revert back certain parts of the code to the Feburary 22nd build release. So making further integration to the flow was one of the major challenges we faced in the project. But we were able to do it and soon after we also realised the necessity to rebuild OpenCV with CUDA, Facebook’s code had built OpenCV without CUDA support. Also, the error logs from the build are hardly intuitive, like issues just seen as linking error, but actually requires CUDA enabled OpenCV. Given that the entire code was written on an Open CV / C++ Multithreaded framework, we had 2 design approaches, reinvent the wheel and write CUDA kernels from scratch for all the Open CV implementations or utilize the OpenCV CUDA libraries intelligently to make an effort at obtaining speedup at significantly less loss in quality by understanding and modifying the algorithms. We chose the latter approach for the most part, and later also attempted the first approach for a better understanding of the code behaviour.
Approach
Profiling
With a view of accelerating the components of the current algorithm that are primary hotspots of performance bottle neck, we started with profiling the current implementation. We also tried to identify the family of computation certain parts of the code were belonging to, for future replacement with better efficient OpenCV CUDA Kernels. We also reviewed the algorithm for critical sections and non critical sections in correctness aspects. After getting an initial phase wise break down of processing time of the algorithm, we noticed that computing optical flow and sharpening are taking up almost 85-90% of the overall processing time.
Computing optical flow being the highest, we dived deep into the code and identified that optical flow generation is computed 28 times with different sizes for each adjacent pair of frames. Also, computation of flow at each pixel is dependent on flow value of pixel at previous position, making that phase of the algorithm fully sequential.Identifying possible pixel level parallelism, we felt that SIMD parallelism of GPU would provide us a lot of performance improvement.
CUDA integration
Original Surround360 code uses a multi-threaded implementation to compute flow at image level. Flow for each pair of adjacent images is computed by a separate thread on a multi-core processor. However, computation within each thread can still be parallelized at pixel level. GPU being an ideal candidate for such a case, we decided to integrate CUDA into the current flow. To keep things simple with CUDA integration, we converted the multi-threaded implementation into a single threaded one first.
Current code has lot of dependencies like folly, CMake, OpenCV, glog, etc., For CUDA to be integrated, it has to be made sure that it is compatible and stable with each one of these dependencies. First, we tried to integrate a simple CUDA kernel into the current execution flow. Since only g++ compiler is being used currently, including nvcc and directing CMake to handle picking up different compilers for different files was a tough task. As mentioned above, After fixing a series of comptability and linking errors, we were finally able to successfully integrate CUDA into the existing flow.
Performance Optimizations
Optical Flow
To exploit the pixel level parallelism, we resorted to using GPU CUDA cores. OpenCV CUDA provides an API for computing optical flow using dense pyramidal lucas kanade algorithm, which is similar algorithm being used by the current Facebook implementation. We identified the levels to which the algorithm from Facebook was using optical flow and provided appropriate paramters to the CUDA flow. We replaced the current sequential implementation with parallel Opencv CUDA implementation and observed more than 3x speedup, just for the optical flow phase.
We know that GPU call incurs a significant overhead and will be amortized only when having considerable amount of computation in the GPU kernel. Current algorithm uses a pyramidal structure of computing flow on different sized images to compute an overall optical flow for a pair of adjacent images. For smaller sized images, this GPU kernel launch overhead cannot be amortized and hence it would be lot better to do such computation on CPU itself. To take care of this, we compute flow corresponding to smaller images, on CPU and utilize GPU only for larger compute intensive image pairs.
While just exploiting pixel level parallelism of an frame pair, a modern GPU would be left under utilized. To improve GPU utilization, we re-enabled image level multi-threading. With this, each adjacent pair of images would be processed by a separate thread, which would in turn make calls to GPU to exploit SIMD parallelism on GPU. Careful fine tuning of the argument parameters provided us the desired speedup and the current state of accuracy.
Sharpening
One other hotspot of performance is the final sharpening of the fully stitched images (for left and right eye). The current algorithm uses an iirLowPass filter that computes horizontal and vertical pass separately and subsequently sends the filtered image to sharpening block. Each pass in turn has causal and anti-causal passes each of which iterate through every pixel of the final image. Sharpening a pair of 8k images with such a sequential algorithm takes around 28 seconds. To accelerate this, we again resort to OpenCV CUDA API. Since the API doesn’t already have an iirLowPass filter and sharpening filters. For sharpening, we follow the usual approach of sharpening an image by calculating Laplacian of the image (that detects edges) and then subtracting/adding it to the image itself. With this CUDA implementation, we are able to achieve an acceleration of around 86.5x by taking only around 0.2 seconds to sharpen the final image pair. However, we see some inaccuracies in the images when compared to the one that is produced by original sequencec of iirLowPass filter + sharpening. We are currently looking into the ways to minimize these inaccuracies. We implemented our own CUDA kernel for iirLowPass filter but are seeing some issues with conversion and handling of abstract data types like cv::Mat that are used in current iir filter. With porting the IIR Low Pass Filter to custom CUDA Kernel and then subsequently using Laplacian Sharpening, we expect the image quality to improve further. Finally, unlike our initial sequential implementation of sharpening left and right stitched images one after the other, we use utilize multi-threading to see a huge increase in speedup.
Below is the visualization of time wise division of the algorithm. On left is the depiction of the original algorithm with box sizes proportional to the taken by the phase of the algorithm associated with it. On right is the depicted, the accelerated implementation.
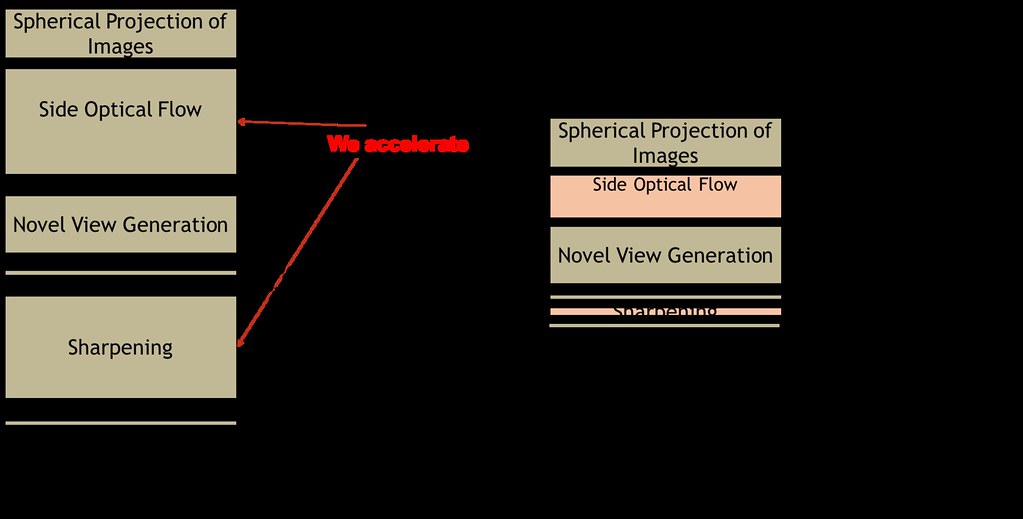
Results
With the accelerated implementation, we have collected results of speedup vs. resolution of stitched images to see a pattern of how our implementation scales with quality of output. Following are the plots that shows speedup plotted against resolution for the phases - optical flow and sharpening. It can be seen that acceleration of optical flow phase scales well when higher quality image are used since more amount of pixel level parallelism can be exploited. However for sharpeniing, most of the parallelism is already being exploited even with lower quality images, and almost no improvement is seen with moving to higher quality images.
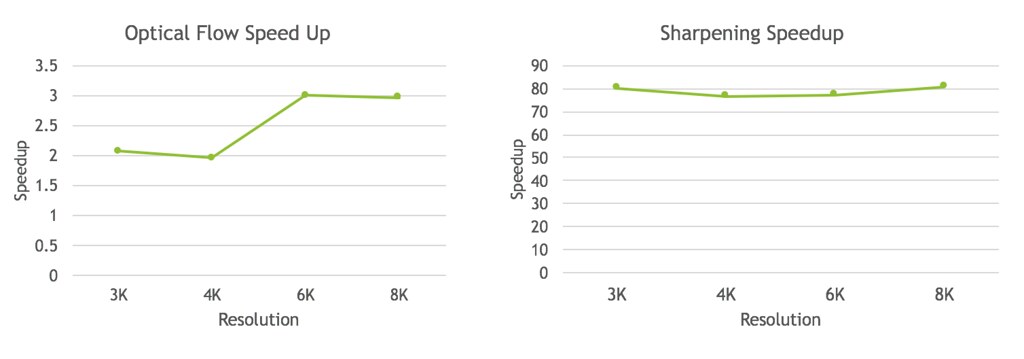
Though we could see a significant 2-3x for optical flow phase and more than 86x for sharpening phase of the algorithm, there are slight dissimilarities in output of sharpening phase, that are measured by the standard metric of structural similarity (SSIM). Almost 93% SSIM on average is seen for output of optical flow phase but sharpening phase sees a somewhat lesser SSIM of 86%. We suspect that using a different algorithm with Laplacian, for sharpening could be the root cause of such dissimilarities. To overcome this issue, we implemented a CUDA kernel from scratch for the iirLowPassFilter based sharpening algorithm of horizontal and vertical passes that Facebook’s implementation has used. Following is the plot that shows speedup against different levels of resolution resultant from the our kernel implementation.
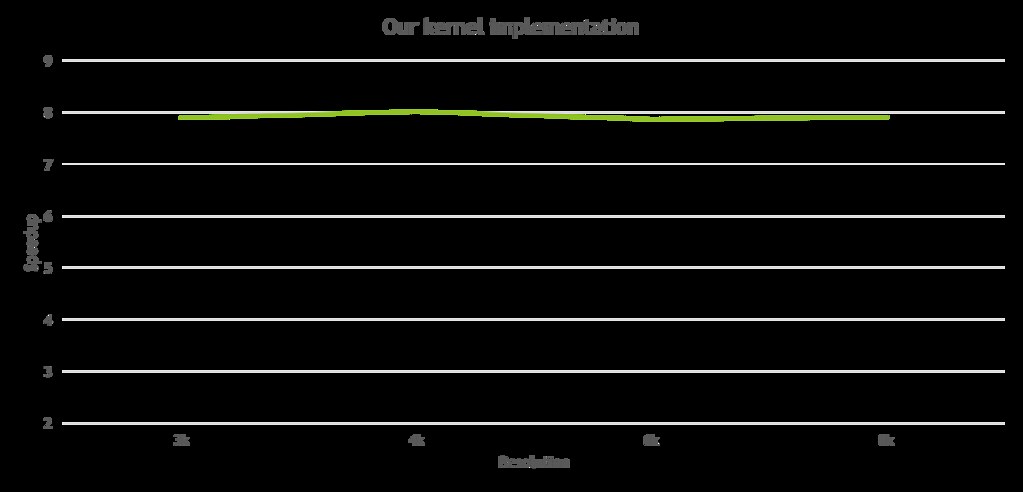
We have noticed one issue with conversion of datatype from 3 split channel image as uchar array to an RGB Mat, and we have not fixed it yet. We are identifying a solution for the same.
Below you can see the resultant renderings from Facebook and our accelerated flow. As visible from the images, we have not significantly lost image perception in spite of our speedup. We see minimal overlaps in the stitching framework implementation (Image comparisions are for pre-sharpening and post optical flow).
Image Renderings
Facebook Rendering

Our Accelerated Rendering

Comparison
To provide a comparison of the pipeline level impact of our speedups,
- The original code takes 66 seconds per frame, thus resulting in 1980 minutes for rendering 1 min of video at 30fps.
- Our accelerated code, if we replace only the blocks that we have worked on ( optical flow + sharpening ) in the original code, the rendering time is 28.3 seconds per frame, thus resulting in 849 minutes for rendering 1 min of video at 30fps (@ accuracy shown in above images).
Speedup Breakdown
We see mainly 6 different stages in the computation of the Facebook Stereo Rendering Panorama Pipeline.
- Spherical projection of the images for each camera.
- Side optical flow for stereo.
- Novel view panorama.
- Flow top+bottom with sides.
- Sharpening
- Equirectangular to Cubemap transformation.
As part of this project, we have accelerated the 2 primary hotspots, Side optical flow and Sharpening and the results are
as follows. All our results have been run on AWS machine (g2.2xlarge: CPU - 8 core Intel Xeon E5-2670 (Sandy Bridge) Processors and GPU - NVIDIA GPU, with 1,536 CUDA cores and 4GB video memory). Results are for a run where CPU rendering of all phases included take 66.3 seconds.
In the below table, Pixel intensity difference is measured as the number of pixels that are having differences in exact pixel values to that of the original implementation from Facebook. But this is not considered to be a standard metric of comparison of similarity between given two images. Structural Similarity (SSIM) provides a better comparison, covering minor translational variance, slight variance in illumination condition, etc., It is widely accepted as a standard metric to evaluate similarity of a pair of images. Also, speedup is the ratio by which our accelerated implementation is faster than that of the original implementation.
| Phase | Original Time | Accelerated time | Pixel intensity diff | SSIM | Speedup |
|---|---|---|---|---|---|
| Optical Flow | 29.7 secs | 9.1 secs | 36.5% | L (for left eye) [0.958112, 0.959504, 0.956474, 0.999628] = ~96% R (for right eye) [0.961018, 0.962793, 0.960144, 0.999633] = ~96% |
3.26x |
| Sharpening | 17.3 secs | 0.2 secs | 23% | [0.877589, 0.842203, 0.842524, 0] = ~86% for 6k Image | 86.5x |